Summer Summary 2013
This time last year I was invited to speak at the Samos Summit, an annual gathering of European open data and eGovernment projects, organised by Yannis Charalabidis and colleagues at the University of the Aegean. Through my role as an advisory board member for the ENGAGE project, I'm delighted to have been asked back again this year to update my talk (slides). As last year, the timing for me marks the end of a long sequence of conferences, workshops and meetings. It's the last big event in my calendar before the summer holidays and as such provides an opportunity to reflect on a hundred conversations.
This year I have even more reason to reflect as my immediate colleagues (Sandro Hawke, Eric Prud'hommeaux, Ivan Herman and Thomas Roessler) have been holding a series of extraordinarily long phone conversations discussing the future direction of the Semantic Web and eGov activities at W3C. It's the output of those deliberations that have been the focus of most of my talks and discussions this summer.
- You See Tables, I see A Graph
- Deep Problem Inspection
- After the Hackathon
- We Could do with a Little Help Here
- This is Getting Serious
- Something to be Excited About
- Summary
You See Tables, I see A Graph
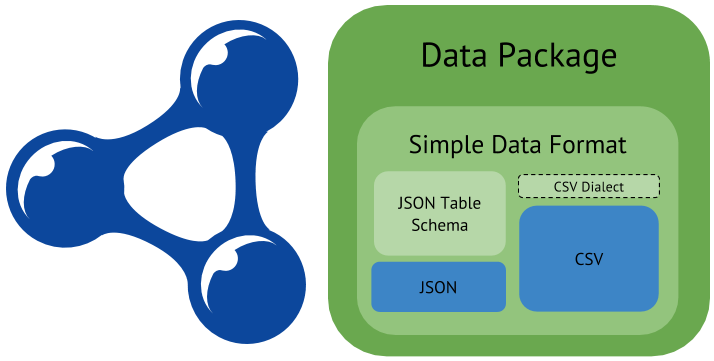
The first issue the W3C Team addressed was the substantial difference in approach to open data technologists taken by those who think in terms of data as something that comes in a table that can be interpreted and visualised in some way, and those who think of data as a series of nodes in an infinite graph that can be traversed and that is constantly being enriched. In other words, the CSV folks and the linked data folks. I was criticised at one of the talks I gave recently for being too technical to a non-technical audience. Well, sorry, but a) I work for a technical standards body, and; b) the technology chosen by an individual reflects his or her philosophy. And philosophical differences matter.
It was this difference that we wanted to address by holding a workshop to which we actively encouraged both 'sides' to attend. Billed as a joint effort by W3C, the Open Knowledge Foundation and the Open Data Institute, and hosted by Google, the immediate outcome of the Open Data on the Web workshop is a planned working group that will attempt to bridge the gap between tabular data and other formats. In tabular data, the structure is revealed in the rows and columns; in linked data it's those links that convey the structure. Can the two be bridged? Of course they can – you just need to know row and column headings, the data types and, sometimes, annotations for particular data points. The CSV on the Web WG will work out a standardised way of encoding that data.
Metadata for tabular data can be used to transform the original into other formats but it can also be used to enrich representations of the tabular data itself – in particular it can be used to generate RDF annotations for tables in HTML pages. This is not a trivial use case. Try doing a Google search for something statistical like the population of Greece. On the results page you'll see not just search results but a time series graph of population and other data. That's Google using sources like World Bank and Eurostat data directly in its Knowledge Graph and presenting it to users. The person behind that project, Omar Benjelloun, is also the person behind DSPL which is a method of providing metadata for tabular data for easy visualisation.
Microsoft has a similar product. The Data Explorer function in modern versions of Excel allows you to find and load tables of data directly. Where do those tables come from? Wikipedia — and there are plans to extend that to make use of open data resources.
My hope is that tabular data, linked data, OData, Property Graphs and more will play more nicely with each other. If we can automatically transform data between them all, the religious wars can end (well, we can dream).
To Do List 1: make transformations between formats so easy that technological distinctions become less relevant.
Deep Problem Inspection
The CSV on the Web working group is W3C's method of offering a solution to an identifiable problem and the road ahead actually looks pretty easy. But the workshop threw up more problems that are going to be harder to solve. The UK National Archives' John Sheridan set the mood of the Open Data on the Web workshop when he talked about building the open data house on sand rather than rock, i.e. warning that there is a danger of the whole thing collapsing. One can adduce strong evidence that open data is alive and well, gaining, not losing political support, but is it sustainable? Do we have a self-sustaining ecosystem in which data from the public sector, the research community, the cultural heritage domain and the private sector is being published, sought out, aggregated, repurposed, visualised, augmented… used?
Enrico Ferra and Michele Osella continue to research commercial business models for open data and services like the transport API from Plāçr show what success looks like; in brief: data for free, service for a fee. But it's clear that some needs are not yet being met.

Data publishers are like any other author. They want readers and they want recognition. When Rupert Murdoch put a paywall between his online papers and their readers did the readers complain? No. But the journalists did, as their readership dropped by 98%.
Just like authors and columnists, what data publishers really want is to feel that their work is valued, that their efforts are worth it.
At a recent event around transport data I had a deeply depressing conversation with two members of staff at my local authority (Suffolk County Council). "At our place no one really sees the point of publishing our data because no one knows what anyone would want to do with it" (I paraphrase only very slightly). It's a classic open data excuse. Finding a way for data publishers to be able to see that their data is important to others is the best answer to this one. As noted in last year's summary and, I'm sure, as in next year's, the more examples that we can point to of local authority data being used, the rarer attitudes like that in Suffolk will become.
To Do list 2: make it easy for data users to signal to publishers that their work is appreciated, especially if it's free.
After the Hackathon

The first time I spoke publicly about open data was in October 2010 in Brighton. This was at the time when the focus of my work was shifting from mobile Web to open data. The call from the developers at that event then was the same as it is now: if I'm going to invest my time and effort building stuff that uses your data I need to be able to trust you to keep it available and up to date.
The Open Data Institute's Data Certificate is a big step along this road. Data publishers fill in a questionnaire that then generates a certificate showing the publisher how well they're doing. At the time of writing, the certificates are not machine readable but they soon will be. The questionnaire highlights the need to make a commitment to maintaining the data set and gives information about the quality of the data. Those are crucial first steps in establishing trust between publisher and developer. But we need more.
The main finding of the UK's Shakespeare Review was that governments must develop and publish a national strategy. Excitingly, this was echoed (copied and pasted?) into the G8 Declaration. The provision of a data infrastructure cannot be entirely ad hoc. That was a good start, yes, but now we need to get organised. Long term financial investment in the provision and use of open data needs a framework so people know what to expect, and that make clear commitments.
As well as the G8 declaration, open data in Europe got a boost in June when the revised Public Sector Information Directive passed its last hurdle. Member States now have two years to enact legislation to bring it into force. For a discussion of the PSI Directive, see the excellent blog post by Ton Zijlstra and Katleen Janssen. These are both strong commitments that should give investors confidence in open data as an idea, but in the end, organisational commitments have to be implemented by individuals.

Here is one such individual.
I've not actually met Stuart Harrison (Pezholio) but he's well known in open data circles in the UK as he was an early adopter and early implementer of open data at Lichfield District Council. If I know one local council in Britain where I can get up to date info on, say, allowances paid to councillors, it (was) Lichfield. And yes, thanks to Pezholio's work I see that such a data set is available. Latest version? 2010-2011 (broken links removed).
Oh dear, what happened?
Look around the data available from Lichfield and it's clear what happened. Pezholio, one individual, got another job (at the ODI).
Organisational commitments on data quality, update cycle and more must not be dependent on an individual who, in effect, represents a single point of failure in the system. We can't force this on organisations, but we can incentivise it by making make such commitments public and machine-discoverable. Politicians tend to get caught out when their promises go un-met.
To Do List 3: Make it easy for data publishers to make machine readable commitments concerning the quality and timeliness of their data.
We Could do with a Little Help Here

During the Open Data on the Web workshop I was struck by the number of high profile organisations whose presentation ended with words to the effect of "and I'm hoping you can all help us with this." Many organisations can see the potential of open data and want to participate. Of those, many recognise the added value and potential of using a linked data approach, but it's not their speciality. They need help.
Now, there is a lot of help available in the form of tutorials and publications, not to mention consultancy, but as with any sphere of activity, there's plenty of scope to offer more help, guidance and tooling.
Like LOD2, the ENGAGE project is an example of the kind of practical help that is needed to make it easier for researchers to contribute to and benefit from open data, but different organisations need different sorts of help. Some organisations are willing in principle to open their data but they're unsure what kind of data they should publish and what sort of guidance developers need. Saying "just publish whatever you've got bearing in mind the 5 Stars of Open Data" really isn't good enough. What they're after is genuine interaction with data users, emphasising the point made about publishers wanting recognition for their effort.
To Do List 4: provide more guidance on data publishing and data consumption.
This is Getting Serious
It's worth noting that the Research Data Alliance is now up and running, addressing the specific needs of the research community in relation to the publication of data. The volumes of data being discussed there will far outstrip public sector data. Disciplines like astronomy and genomics generate huge volumes and there's the special case of CERN where data volumes are staggering.
The PRELIDA project is addressing the issue of long term storage of linked data. The questions there are not so much what should be kept as what can be thrown away. If linked data is generated by transforming a relational database do you preserve the triples or the original RDB + transformation or did you do a bit of manual cleaning up that you also want to preserve? These kind of questions only arise when a community begins to mature. I take the existence of both the Research Data Alliance and PRELIDA as very encouraging.
Something to be Excited About
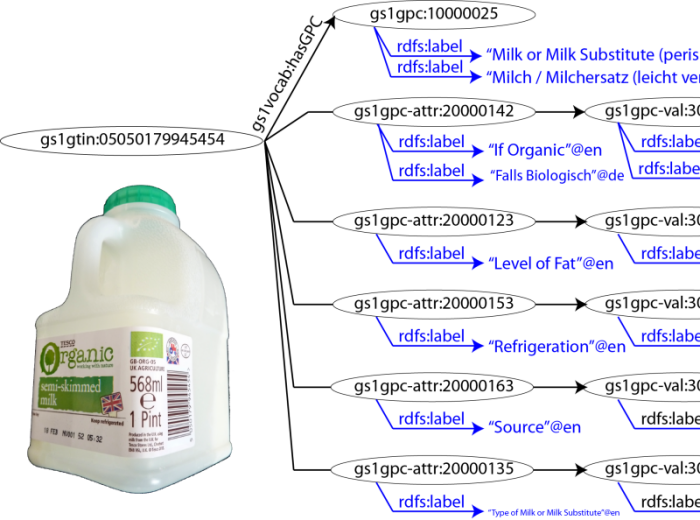
40 years ago a checkout went beep for the first time when a customer at Marsh's supermarket in Troy, Ohio bought a packet of Wrigley's Spearmint Gum (source video, at ca. 2':30"). That was the beginning of a global standard we're now entirely used to. Properly called a GTIN number, product identifiers are encoded as bar codes on just about everything. Wouldn't it be great if those identifiers were available as linked open data?
They soon will be.
The body behind GTIN numbers, GS1, produces other identifiers too that are just as important for the manufacturing, distribution and retail industries, including product types. They now have an active programme (code named Digital GS1) to make as much of their data available on the Web as possible. That's a huge step forward in my view, for the Internet of Things, eCommerce and smart applications..
The ecosystem around products can extend from manufacturers putting their catalogues online, through retailers making data about their stores available to any number of applications. Lego Digital Designer allows (allowed) you to design your own model and order all the parts to make it for real. Digital GS1 means you don't have to be restricted to models made of bricks, you'll be able to source pretty well anything and find where to buy it. For an idea of the kind of thing developers already want to do with GTIN numbers, see Product Open Data.
As IBM's Phil Tetlow put it; Metadata is advertising.
To Do List 5: Encourage the development of a self-sustaining data ecosystem.
Summary
The political backing remains strong and there are serious efforts being made to make the promise of open data a reality. However, as things stand the sustaining force is the politics. If the movement is to survive and actually deliver tangible results then we must work to replace the political will with hard headed self-interest. At W3C we're undertaking several new projects (all subject to member approval and W3C process):
- the CSV on the Web Working Group — how to create something like 5 star linked data without a triple store (1);
- the Data Best Practices Working Group 2, 3, 4, 5 (building the ecosystem, offering guidance);
- extended vocabulary services (a welcoming environment and persistent, trusted hosting for vocabulary developers, with an emphasis on multilingualism);
- exploring other issues such as RDF validation and, through the forthcoming Smart Open Data project, how to work with linked data and geospatial data.
That's what W3C is doing, but that's only a subset of what needs to be done. What are you doing?