What’s wrong with PDF and why is HTML better?

This week, GS1 published its first ever standard in HTML, i.e. as a Web page, not as a PDF. The reaction from the Web community was something like ‘about time too’, but from two GS1 colleagues who I like and respect enormously it was ‘why, what’s wrong with PDF?’ I’ve been asked more than once to highlight the advantages of HTML over PDF so here goes.
PDF (Portable Document Format) has a long history which is comprehensively documented in Wikipedia. It was designed to offer a means through which I can create something that you can see on your screen and/or print out that is exactly as I intended, including layout, fonts, colours and more. It does this very well.
Furthermore, PDF has the capability to include not just text and images but data as well. Only a few years ago, Larry Masinter and Leonard Rosenthal at Adobe were championing PDF as a means of encapsulating and sharing Linked Data. They pointed out, not unreasonably, that PDF offers the ability to publish scientific papers with the data itself embedded. Empirical data and analysis all in one bundle. That’s good science, right? Last year, Jeni Tennison and others took up the charge and set about improving the way in which PDF is used for open data.

So why does the Web community hate PDF with such a passion?
I mean, really, viscerally despise it?
There are several reasons that I'll try and artculate.
PDF has a fixed width, HTML flows
Whether you’re reading this on your mobile or stadium-sized screen, this page flows to fit. It’s called Responsive Web Design and has been around since Ethan Marcotte came up with it in 2010. PDF is designed specifically not to do this. If you read a PDF on a mobile you’ll probably be zooming and scrolling all over the place, or you’re young enough to read tiny weeny writing…
PDF can’t even handle the change from US Letter size paper to A4 as used everywhere else in the world. PDF is good for printing stuff out on paper. For screen reading it’s terrible.
PDF does not fully support linkage, in HTML it’s a basic property
You can usually link to a specific page in a PDF document. I did this a lot, for example, in a project I did a few years ago where I wanted to link to specific sections of various PDF documents. The best I could do is link to the page, not the actual section. Compare that with, for example, linking to the definition of the 4Ws in the GS1 Mobile Ready Hero Images Guideline or a specific best practice in the W3C Data on the Web Best Practices.
That’s enough, right there, to dislike PDF. It’s not Web-friendly, i.e. it doesn’t function as part of the Web, but is, at best, an offshoot of it. But there’s more.
PDF is non-functional by design, Web pages can be interactive

700g
Dal Giardino Bolognase Sauce 700g
★★★★★
£1.95

PDF is static with no possibility of interaction. The GS1 Mobile Ready Hero Images work provides an easy example of why this matters. A crucial aspect of that guideline concerns the positioning of information that is not included in the product image itself (because it’s too small) but that must be present right next to it for a consumer to make a purchase decision. Some people put this info in the image tile but off-pack, something that the guideline specifically and explicitly says do not do. So it really matters that the size information in the examples is understood to be outside but adjacent to, the image tile. This is why there is an option to show/hide the crop marks around the images in that document. Reduce the document to PDF and you see the Show/Hide buttons but they don’t do anything (and you don’t see the cropmarks as they’re defined in the CSS as background images).
Interactivity can also make documents more readable. You’ll be very familiar with expanding sections that provide background to the main article you’re reading. Standards documents written in HTML routinely include hyperlinks to definitions and other details elsewhere in the same document to avoid repetition.
Stylesheets and scripts can be centrally managed to update all documents, PDFs are locked
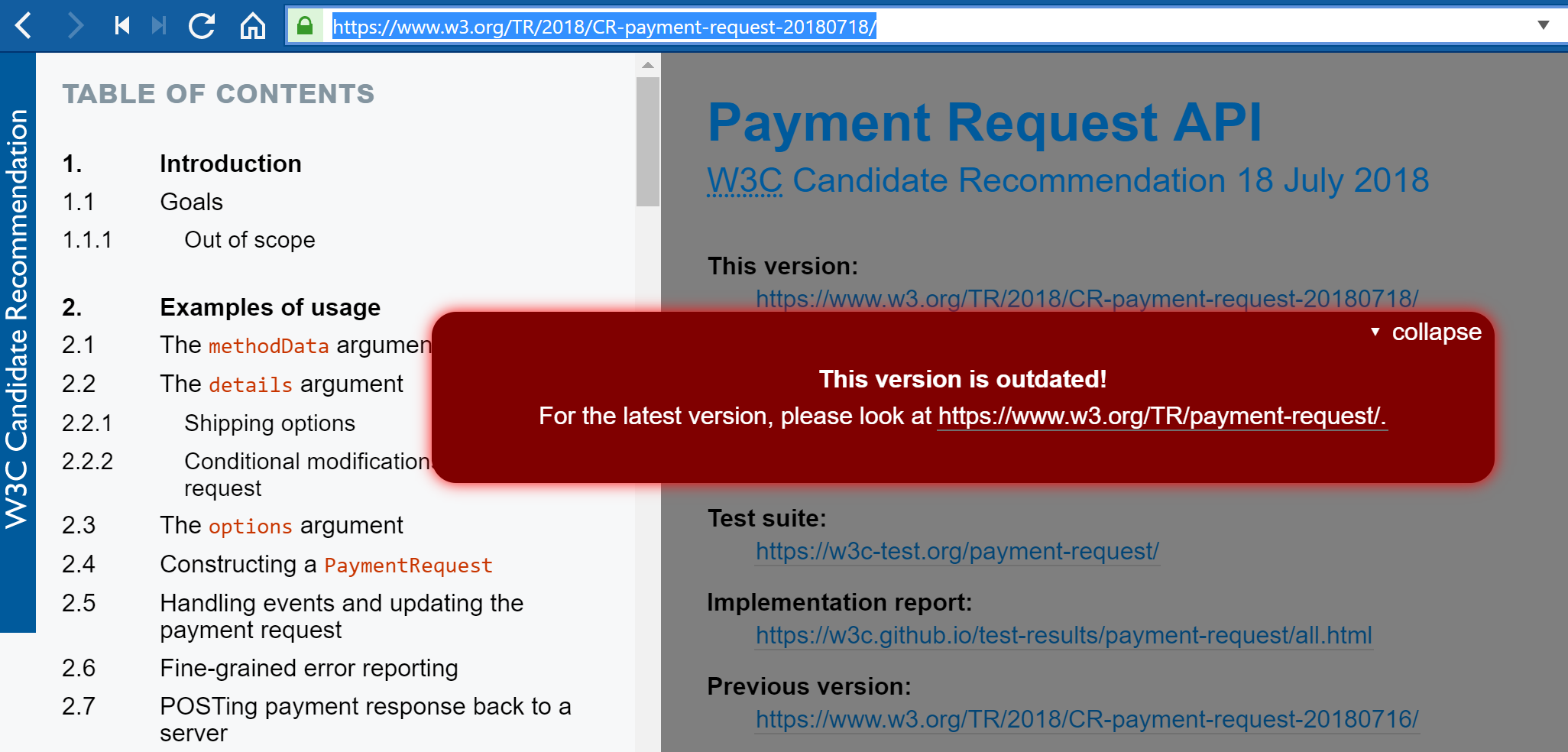
Again, this is a design feature of PDF – you can’t update it by updating an externally linked resource like a stylesheet or a script library. You might want to do this if you change your company’s logo or corporate imagery, or do something like W3C does for all its documents for which there is a later version. See, for example, the Web Payments API draft from 18 July 2018. There’s a later version and so you get a warning. That’s driven by a script that looks for a later draft and, if found, puts that warning in place. That system was introduced in 2017 without any need to update the documents themselves. PDF can’t do anything like that.
Data is hard to access in PDF, easy in HTML

Depending on how the PDF was created, extracting data from tables within a PDF is either easy or hard. Peter Murray-Rust has done extensive work on this and, rightly, gains huge respect for doing so. The PDF Liberation GitHub Repo has more from him and others.
Such tooling is possible as PDF is a royalty-free ISO standard so that anyone can create tools for it. It will cost you 198 Swiss Francs to buy, but you can do that and then build your tools. Take a look at those tools. They’re only for developers and are pretty specialised.
The problems are exacerbated when, rather than including an actual table in a PDF, authors include a screenshot of a table. It looks the same – that’s what PDF is about – but it’s a whole different ball game if you want to get at the data itself, or the individual paragraphs etc. Extracting information from an image is much, much harder and error prone.
This actually points to the most unfair aspect of this discussion. PDF has some very good functionalities. It can do all sorts of things that people say they want. But few people use those functions. What it actually gets used for is to create a flat, static version of a Word doc or PowerPoint presentation designed for printing. The tools are there to use PDF properly – but they’re rarely used. Again, this is what's driving the work at the Open Data Institute on this topic
PDF is easy, why complain?
Aye, there’s the rub. You can work in Word and print it out as a PDF directly. Job done. How the heck can anyone edit HTML?
Well, actually, there are some pretty good tools for HTML editing. Most Web sites are created using content management systems like Wordpress, Joomla or Drupal which give you a Word-like interface through which you do, in fact, create HTML. Blue Griffon is probably the best standalone HTML document editor around and, like those content management systems, designed for non-specialists. Although, OK, I admit, I just use a text editor because I can write HTML in my sleep.
But Word creates the table of contents and numbers my figures and sections for me
So can scripting. The Mobile Ready Hero Images guideline uses a number of scripts to do all that. The table of contents is auto-generated, the sections are numbered through CSS, the figures are all numbered automatically and so on. The best scripting library around for this is W3C’s re-spec which I used some of and that (Dutch geospatial standards body) Geonovum has fully customised.
How can you track changes in HTML?
Easy. Use the W3C’s diff tool. I used this to generate deltas between versions of the MRHI guideline, for example.
Summary
| HTML | |
|---|---|
| Static | Can have dynamic elements |
| Page-level links at best | Any element can be linkable |
| No in-document links | In document links |
| Fixed width | Flows to any width |
| Immutable | Can be amended through externally linked resources if so desired |
| Data and other elements hard (or impossible) to address or extract | Data and other components easy to address and extract |
| Easily generated using common software, especially Microsoft Office | Requires use of different tools |
GS1’s publication of the Mobile Ready Hero Images guideline is a pilot and may well lead to this being the norm. Let’s hope it works out.