A history of the ideas in GS1 Digital Link
Today sees the formal publication of GS1 Digital Link 1.1 [DL1.1], something I've been working on for a while, along with many other people. From a Web-technology perspective, it's a formalism of a particular kind of node in the Linked Open Data cloud; or maybe it's a hypermedia service endpoint, or a linkset, or any of many more ideas that may or may not be familiar to you.
Is it new?
Hardly …
Introduction
One of the things I say repeatedly about GS1 Digital Link is that it does not involve any new technology. It takes the identification system first used commercially on 26 June 1974 [Marsh74] and puts it onto the World Wide Web, the concepts of which were first formalised by Tim Berners-Lee in March 1989 [IMP]. Both technologies are mature, massively implemented, and form part of the modern world.
On this basis, at least a basic version of GS1 DL could have been launched on 7 August 1991, the day after the first Web site went live at CERN, or maybe 1 May 1993, the day after CERN put all the code for the Web in the public domain [BW].
The opportunities that arise from the merging of these two technologies have been known for years, if only because they are obvious. So what, if anything, is actually 'new' about GS1 Digital Link? In the following sections, I'll look at each component in turn.
Contributions from Jeanne Duckett (Avery Dennison), Keith Jeffery (independent), Simon Dobson (University of St Andrews), Herbert Van de Sompel (DANS), Mark Harrison and Henri Barthel (GS1) are gratefully acknowledged.
URI structure
The fundamental basis of GS1 DL is the URI structure. This was defined normatively in version 1.0 of the standard [DL1] which still carries its original name of 'GS1 Web URI Structure'. GS1 defines many application identifiers [AI] and these fall into two broad categories:
- item identifiers, such as GTINs to identify trade items, GLNs for locations and companies, SSCCs for shipments and more;
- attribute identifiers, such as measured weight, expiry date, ship to address etc.
For several identifiers, you can add more specific identifiers. The GS1 Digital Link standard talks about primary keys and key qualifiers. The obvious example here is of a GTIN as a primary key and a batch/lot number as a key qualifier. The batch/lot number refines the identifier and, therefore, it matters which order things are in. In contrast, it doesn't matter at all which order one provides attribute data like expiry date and measured weight.
This distinction is very familiar in information science: they're classes, sub classes and properties, and it's this that gives us the general structure of a GS1 Digital Link URI:
https://example.com/[{path/}]{primaryKey}/{primaryKeyValue}[/{keyQualifier}/{keyQualifierValue}]{?attribute=value}
↑ ↑ ↑ ↑ ↑ ↑ ↑
--------------------- ---------------- ----------------- |
| | | |
Resolver Exactly one 0 or more 0 or more attribute
Primary key/value key qualifiers name=value pairs
We start with the resolver's location, which is largely irrelevant in GS1 DL and doesn't form part of the identifier, and then you get the primary key and its value. Any key qualifiers and their values follow, in order, separated by slashes. The standard has several pages of detail on this, expressed using ABNF [RFC5234], but that primarily gives details of specifically how to encode GS1 identifiers. It would be perfectly possible to define a more general standard for any identificaton scheme that followed the same underlying pattern (and this is a distinct possibility at the time of writing).
Is this a new idea for GS1 Digital Link? Hardly - this is basic identifier structure in that you become more precise as you work left to right. That idea is present in any globally unique ID scheme including GS1 identifiers, DOIs, LEIs and more. The best known document that suggests the specifics of doing it this way in HTTP URIs is Cool URIs for the Semantic Web [Cool-SW], a W3C Note from December 2008 that distils ideas that had been around for many previous years. Notice the first example:
http://www.example.com/- the homepage of Example Inc.
http://www.example.com/people/alice- the homepage of Alice
http://www.example.com/people/bob- the homepage of Bob
And that's in a section talking about 'the old Web'1 The URIs are structured so that, from left to right, you go from the organisation to its people to a specific person. A more formal approach to hierarchical URIs was set out by Leigh Dodds and Ian Davies in 2012 [LDP]. All that work was inspired in part at least by TimBL's note in 1998 called Cool URIs Don't Change [Cool-URI]. That document was about URI persistence but the key to that persistence is … URI structure.
Additional note 2020-06-22: I've been made aware of Zack Bloom's excellent article on the history of the URL [Bloom]. It covers a great deal of ground that isn't of direct relevance here but does point to the history of the hierarchical structure of paths in URLs that goes back to a 2 hour conversation with Albert Einstein.
Linked Data doesn't generally make use of query strings and GS1 DL barely does except in querying the resolver. Query strings are passed on to the target URL and where you put more or less anything you want/need to pass on to the eventual server but they don't (normally) play a part in identification as such.
There is nothing new about structured URIs.
Link types
Take a look at Figure 1 from TimBL's original proposal from 1989.
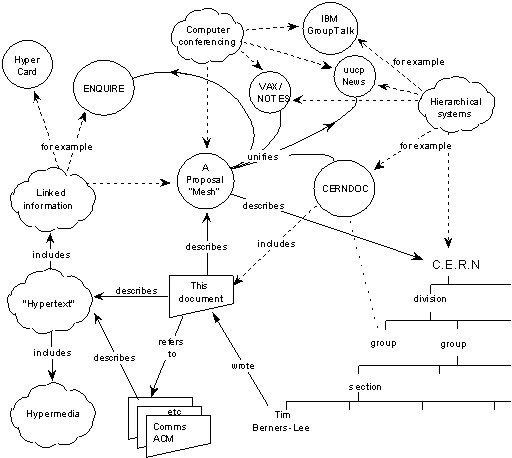
Notice that each entity — be it a person, a concept, a document or whatever — is linked to other things via lines that are annotated with labels like 'describes', 'unifies', 'refers to' and so on. Those are known as relationships and the idea of an Entity-Relationship model goes back to well before the Web and before it was formalised by Peter Chen in 1976 [ER]. GS1 Digital Link's 'link types' are relationships or, to give them their full name, link relation types.
Search for link relation types and you'll soon end up at the IANA Link Relation Types registry which was first created in 2005. But we can go back further than that. Link types are discussed by name in HTML 4.0 [HTML 4.0] but they're used in HTML as values of the rel and rev attributes which go back to [HTML3] from March 1995 (see Dave Raggett's History of HTML [DSR]).
There is nothing new about link types.
Automated link-following
The idea of being able to programmatically discover a set of typed links, and to act on one or more of them, is, again, not a new concept developed for GS1 DL. Hypermedia as the Engine of Application State [HATEOAS] explores this idea and is based on the Hypertext Application Language [HAL] that dates back to at least June 2012. That in turn is based on Roy Fielding's original work on Representational State Transfer [REST] from 2000. Roy Fielding is one of the leading architects of the Web, responsible for, among other things, the original definition of a relative URL [RFC1808] in 1995, and working with TimBL and Larry Masinter on the URI specification in 1998 [RFC2396].
There is nothing new about automated link-following.
Resolvers

One of the most widely used 'resolvable identifiers' online today is the Digital Object Identifier (DOI), which became an ISO standard in 2012 [ISO-DOI] having been introduced more than a decade earlier. The definition of 'resolution' offered by the International DOI Foundation is: [DOI-HB]
Resolution is the process in which an identifier is the input — a request — to a network service to receive in return a specific output of one or more pieces of current information (state data) related to the identified entity: e.g., a location (URL). Multiple resolution, that is made possible by the Handle System used as the DOI resolution component, is the return as output of several pieces of current information related to a DOI-identified entity — specifically at least one URL plus defined data structures allowing management.
When DOIs were introduced in 2000, one of the first resolver services it used was the Handle System which first went live in autumn 1994, having been developed by one of the co-inventors of TCP/IP, Bob Khan. Back even further - the concept of resolving an identifier online goes back at least to the introduction of the Domain Name System in 1985.
There is nothing new about resolvers.
Querying a resolver
A feature of GS1 DL is that you can append a URI with a value for the linkType parameter and, if it's available, the resolver will redirect to that, rather than the default. Is this new?
We are now so familiar with the idea of the query string in a URL that is used to query a database that it's hard to imagine that this wasn't the norm when the Web was first introduced in 1991. From what I can tell, the now very familiar ?param1=value1¶m2=value2 syntax was developed by NCSA, University of Illinois, as the Common Gateway Interface (CGI) in 1993 [CGI] and formalised in 2004 [RFC3875].
Work undertaken by Simon Dobson (broken link removed), Victoria Burrill and others gives and indication of the landscape in the early 90s [DobsonBurrill]. The kernel of their work is that the Web was being used in those early days to link to and from static documents. Working at the Rutherford Appleton Laboratory, led by Keith Jeffery, Dobson and Burrill saw that the Web could be a distributed database of queryable data if it were embedded within the HTML and that those documents themselves could be generated by querying the underlying relational database. There are a lot of ideas we now take for granted in those papers which might be considered as a forerunner of the Semantic Web/Linked Data and schema.org, of which the GS1 Web vocabulary, including its link types, is an extension.
Dobson & Burrill don't mention query strings but they do build on the key underlying idea: if your URL identifies a source of data, you can include a query that can be run against that data source. As Keith Jeffery notes, for this to work, there had to be a notion of a query and, as we've seen, query strings were around by then and were included in the original URL specification in 1994 [RFC1738].
Alternatives to the query string have been suggested. Tim Berners-Lee wrote about Matrix URIs in December 1996 [Matrix]. In that system, parameters appear within path segments and are separated by semicolons. Here's a key section:2
The analogy with procedure call holds still when looking at combined forms: The hierarchical part of the URL is [parsed] first, and then the semi-colon separated qualifiers are [parsed] as indicating positions in some matrix. As an example let's imagine the URL of an automatically generated map in which the parameters for latitude, longitude and scale are given separately. Each may be named, and each if omitted may take a default. So, for example,
//moremaps.com/map/color;lat=50;long=20;scale=32000might be the URL of an automatically generated map.
That paper goes on to make interesting reading around things like relative URLs with matrix parameters that I can imagine might be useful in future versions of GS1 Digital Link but the important point for now is that the idea of sending query parameters to an identified resource, whilst not there on day 1 of the Web, was introduced soon afterwards.
There is nothing new about querying an identified data source on the Web.
Incidentally, TimBL's work on Matrix URIs has inspired more recent work on resolving Decentralized Identifiers [DID Resolution]. There are analogous ideas in that work around an identifier associated with a small set of links that can be accessed directly by including the relevant query.
Contextual response
The primary reason that GS1 DL appears 'new' to some folks is simply that you don't need to know how the Web works just to use it. Some of the features that people use every day aren't immediately obvious. To highlight some of these, i.e. to show how powerful the Web already is, an exercise I often do when talking to groups about GS1 DL is as follows:
- Invite everyone to visit their social media homepage (usually Facebook). Everyone sees something different at the same URL.
- Invite everyone to look at my calendar. What they see is when I'm busy. What I see is what I'm doing - that's because I am authorised to see more information than others are.
- Invite people to visit the GS1 Global office contact page. This is a really good example of a Web page that responds differently depending where you are. You should see the address of your local GS1 office - whichever country that may be in (there are currently 114 GS1 offices around the world).
- If I have a multilingual audience, I invite them to go to the Google homepage. If your browser is set to a language other than English, it will offer you the option of searching in your language or English.
These are all examples of the end user seeing something different depending on factors such as:
- who they are;
- whether they're authorised to access content or not;
- where they are;
- what language they speak.
Some of these factors are part of the original HTTP specification [RFC2068], notably language and authorisation. GS1 DL also makes use of HTTP's content negotiation, meaning that you can request a given resource in different formats like HTML, XML or JSON.
What about location?
There are two methods of detecting a user's location. One is based on their IP address, the other via an API to whatever system the user's device has for detecting its location. The latter — the Geolocation API [GeoLoc] — is only accessible by an application running on a device and resolvers have no access to that. In contrast, the IP address of the user is always known to a resolver as that is the point on the internet to which the response must be sent. But … the allocation of IP address blocks is administered entirely separately from the HTTP specificiations and can change. Although there are any number of services that allow you to look up the approximate geolocation of a given IP address, to make this part of HTTP would require a commonality of approach that is not deemed necessary.
As a consequence, GS1 DL does not include a specific field for location that would require resolvers to act accordingly. However it does include the optional context variable. Resolver implementations are free to use the context variable for whatever they want but one possibility is to use it for locations, as in "give me the product information page relevant to Jordan" or "give me the product information page relevant to Ghana".
In terms of the history of ideas, note the example used in that document about Matrix URIs from 1996 [Matrix] - it's a URL with a query about a location in it, and that's what GS1 DL supports via the context parameter.
There is nothing new about querying a resource as it relates to a specific location.
Redirection
Redirecting from one server to another has always been part of the Web — it's part of the original HTTP specification from January 1997 [RFC2068]. But, like so many things in computing, that basic idea goes back well before then. For example, even on the pre-Web Internet, the Internet Control Messaging Protocol [RFC777] from 1981 includes redirection - 8 years before the Web was conceived.
There is nothing new about redirection.
Smartphones and barcode image processing
If the technology and ideas used in GS1 DL are all so old, an obvious question is "why has the standard only just been developed now?" From what I can see, there is no single answer to that question, but I can state that the ease of access to information is what's behind increasing consumer demand for information about products: What's in my food? Where did it come from? What's the carbon footprint? Is it sustainably produced? And so on. More than any other device, it's the ubiquity of the smartphone that is a driver of consumer demand here. Within business processes, it's about simplifying an ever-more complex set of digital resources and APIs. In that context, the fact that GS1 DL is only now emerging as a standard becomes more understandable.
But are camera phones new?
According to Wikipedia, phones had cameras as long ago as 1999 — and the idea of video calling someone has been around in science fiction for much longer of course.
What about using a camera to scan a barcode?
When Sharon Buchanan served Clyde Dawson in June 1974, and for many years afterwards, scanners were all laser-based. Image processing — i.e. the computing necessary to detect and process a barcode from an image — didn't come along until the late 90s. See, for example, Industrial Image Processing: Visual Quality Control in Manufacturing from 1999 [IIP].
The first scanners — like the one used in 1974 — were fixed into the checkout desk. Handheld scanners arrived shortly afterwards, like Symbol's LS7000 in 1980. You can go back even further to the RotoMark handheld scanner from 1969 although that didn't use barcode technology as such. That particular scanner was developed by Monarch Marking Systems, Dayton Ohio, which was wholly acquired by Avery Dennison in 2008

Linking a barcode to a computer database?
As good a definition of a barcode scanner as you'll find anywhere is this from a 2015 article:
… while some barcode readers use lasers, and others use lights or cameras, they all have one thing in common: Their basic purpose is to translate the barcode into an electronic code and send it to a computer or database.
That was as true in 1974 as it is today.
What about smartphones as scanners?
The easiest date to apply to the advent of a cellular phone that included a camera and that had sufficient computing power to process the image of a barcode to extract the identifier is the date that Steve Jobs first showed the iPhone to the world: 9 January 2007 (earlier PDAs like the Palm Pilot didn't have a camera).
So let's recap. We have:
- scanning a barcode and sending the identifier to a computer or database since Bernard Silver and Norman Joseph Woodland's work in the late 1940s/early 50s;
- handheld laser scanners since 1980;
- camera-based scanning since at least 1999;
- cameras in phones since 1999 (although not in a device with sufficient computing power to carry out image processing);
- handheld devices with sufficient computing power to carry out image processing (smartphones) since 2007.
There is nothing new about a handheld barcode scanner, like a camera phone, sending an identifier to a database.
Compression
The issue of compression came up very early in the development of GS1 DL. Some data carriers have very restricted capacity, or rather, the amount of space available on a product might restrict the size and therefore the capacity of the data carrier. A GS1 DL URI containing anything more than a GTIN and with anything other than a short domain name quickly exceeds such a restrction so we needed a means of:
- compressing a GS1 DL URI as much as possible given the other constraints;
- being able to decompress the URI without needing an online look up (so things like bit.ly and tinyURL.com are not solutions);
- the compressed GS1 DL URI must still function as a URL without any processing.
There really is only one way to do this. It's all about character sets and binary numbers.
If you want to be able to write any number, and any Latin character in both upper and lower case (A-Z and a-z) then you need an 'alphabet' of 10+26+26=62 characters. But you also want to be able to punctuate, so you need things like a space character plus .,/:;!"'+-=_ and more. So maybe you want to use the ASCII character set [RFC20] which has 127 characters, each of which is encoded using 7 bits (27 = 128). But, hang on, there are so many more characters than that. There are accented characters, for example, like éèöô plus things like ©®™↑←↓→‘’~#[]{}*&^%$£. And we haven't even started on non-Latin characters.
In reality, there are tens of thousands of characters (there are over 50,000 Chinese characters alone). The 2017 version of the Unicode standard [Unicode] lists 137,994 characters, and details how these can be encoded using one or more bytes per character, that is, at least 8 bits per character. That means that to store the lower case letter a, what's actually stored is 01100001 (8 bits). But, if you restrict yourself to only 64 characters then, you can store the same letter using just 6 bits (26 = 64) meaning that the letter a can be stored as 011010 (6 bits). So the basic method of compression is:
- write out your string in binary with 8 bits per character;
- now chop that binary string up every 6 bits;
- convert each set of 6 bits into a character from your restricted 64 character alphabet.

This process is reversible with no loss of information.
Mark Harrison did a huge amount of work on this for GS1 DL and used a number of enhancements that apply specifically to GS1 identifiers within the structure of an HTTP URI, but that's the basic technique.
Did Mark invent this?
He's exceptional; but no, he didn't invent this. A number of foundational restricted alphabets were standardised in July 2003 [RFC3548] and if you want to go back further, Louis Braille (1809 - 1852) is credited with inventing "the first small binary form of writing developed in the modern era". David Salomon's book 'Data Compression, the Complete Reference', which inclues this technique, was first published in 1998 [Salomon]. More than a decade earlier, "Data compression: techniques and applications" by Thomas J. Lynch [Lynch], included a discussion of what the author calls "Compact notation", "logical compression" or "minimum-bit compression". This:
takes advantage of the fact that in a given field, each n-bit character word may not have meaningful values over the entire 2n possible combinations. Thus, some characters can be coded with shorter fixed-length words, thereby providing a compression.
Lynch goes on to provide an example of an uncompressed date MMDDYY usually requiring 6 x 8 bits = 48 bits. However, he notes that
- a 4-bit word (16 possible values) is sufficient to encode 12 months;
- a 5-bit word (32 possible values) is sufficient to encode 31 days per month;
- a 7-bit word (128 possible values) is sufficient to encode 100 distinct year values.
Therefore, only 4+5+7 bits = 16 bits is required, achieving a compression ratio of 3:1.
A 1993 publication by Held and Marshall [Held, Marshall] uses the same DDMMYY example, referring to the technique as "Logical compression", and includes information about character sets using less than 8 bits per character, including 5-bit Baudot code, which dates from the 1870s, and 4-bit Binary Coded Decimal (BCD), which played an important part in determining the patentability of software and algorithms in 1972. Held and Marshall also discuss the use of 'header' bits that precede the compressed data payload and which indicate the type of compression used as well as the number of compressed characters that follow. Both of these are highly relevant to the approach taken by Mark Harrison in GS1 Digital Link, but that wasn't his first work in this area. He had worked on compression in the GS1 Tag Data Standard which dates from the early 2000s3. That work includes the USDOD-64 scheme which used 6-bit compaction for alphanumeric sequences (for the CAGE/NCAGE or DODAAC value), and most EPC schemes use integer encoding for numeric strings, to achieve approximately 3.32 bits per digit, rather than 7 or 8 bits per numeric character. Clever? Sure, but …
There is nothing new about lossless compression.
Conclusion
There is nothing new about structured URIs.
There is nothing new about link types.
There is nothing new about automated link-following.
There is nothing new about resolvers.
There is nothing new about querying an identified data source on the Web.
There is nothing new about querying a resource as it relates to a specific location.
There is nothing new about redirection.
There is nothing new about a handheld barcode scanner, like a camera phone, sending an identifier to a database.
There is nothing new about lossless compression.
There is nothing new about GS1 Digital Link
References
- [AI]
- GS1 Application Identifiers
- [Bloom]
- The History of the URL The Cloudflare blog, 5 March 2020. See, in particular, the section on the origin of the path.
- [BW]
- The Birth of the Web, CERN
- [CGI]
- The original documentation for CGI was originally published at http://hoohoo.ncsa.uiuc.edu/cgi/ but is no longer available from that site. The content can, however, be accessed using the Memento Web
- [Cool-SW]
- Cool URIs for the Semantic Web Leo Sauermann, Richard Cyganiak. W3C Note, 3 December 2008
- [Cool-URI]
- Cool URIs don't change. Tim Berners-Lee, 1998.
- DID-Resolution]
- Decentralized Identifier Resolution (DID Resolution) v0.2, Resolution of Decentralized Identifiers (DIDs). Markus Sabadello, Dmitri Zagidulin. W3C Draft Community Group Report (accessed 21 November 2019)
- [DL1]
- GS1 Digital Link 1.0 (published as GS1 Web URI Structure). Mark Harrison, Phil Archer et al. GS1, August 2018 (PDF)
- [DL1.1]
- GS1 Digital Link 1.1. Mark Harrison, Phil Archer et al. GS1, 19 February 2020 (PDF)
- [DobsonBurrill]
- In '94-95, Simon Dobson & Victoria A Burrill published a number of papers related to linking data embedded within HTML documents
- Simon Dobson, Victoria Burrill and Julian Gallop. Semantic mark-up of generalised documents (broken link removed). Technical report WWW/01/94. Rutherford Appleton Laboratory. August 1994.
- Simon Dobson. Data and hypermodels are isomorphic: manipulating hyperdocuments at a logical level (broken link removed). Technical report WWW/02/94. Rutherford Appleton Laboratory. August 1994.
- Simon Dobson and Victoria Burrill. Preliminary results from the database markup of hyperdocuments (broken link removed). Technical report WWW/03/94. Rutherford Appleton Laboratory. November 1994.
- Simon Dobson and Victoria Burrill. Towards improving automation in the World Wide Web (broken link removed). In New directions in software development. British Computer Society. 1995.
- [DOI-HB]
- DOI® Handbook, section 3.1. DOI Foundation, last updated 16 August 2018
- [DSR]
- A history of HTML, Dave Raggett. Published by Addison Wesley Longman, 1998.
- [ER]
- The entity-relationship model—toward a unified view of data Peter Pin-Shan Chen. Published in: ACM Transactions on Database Systems (TODS) - Special issue: papers from the international conference on very large data bases: September 22–24, 1975, Framingham, MA. Volume 1 Issue 1, March 1976, Pages 9-36
- [GeoLoc]
- Geolocation API Specification 2nd Edition. Andrei Popescu. W3C Recommendation 8 November 2016
- [HAL]
- HAL - Hypertext Application Language. Mike Kelly. 13 June 2011, updated 18 September 2013.
- [HATEOAS]
- HATEOAS on Wikipedia
- [Held, Marshall]
- Data compression : techniques and applications : hardware and software considerations. Gilbert Held and Thomas R. Marshall. 3rd Edition, Chichester, West Sussex, England ; New York : Wiley, c1991.
- [HTML3]
- HyperText Markup Language Specification Version 3.0, Hypertext links. Dave Raggett. W3C/IETF draft, March 1995
- [HTML4.0]
- (HTML 4.0 Specification section 13.3.2: Links. Dave Raggett, Arnaud Le Hors, Ian Jacobs. W3C Working Draft 17 September 1997
- [HAL]
- JSON Hypertext Application Language, M. Kelly. Internet Draft 7 June 2012
- [IIP]
- Industrial Image Processing: Visual Quality Control in Manufacturing. Christian Demant, Bernd Streicher-Abel and Peter Waszkewitz. Springer 1999. See, in particular, chapter 5.
- [IMP]
- Information Management: A Proposal, Tim Berners-Lee, 12 March 1989.
- [ISO-DOI]
- ISO 26324:2012 Information and documentation — Digital object identifier system. ISO/TC 46/SC 9, May 2012
- [LDP]
- Linked Data Patterns, A pattern catalogue for modelling, publishing, and consuming Linked Data. Leigh Dodds and Ian Davies. 31 May 2012 (see the section on hierarchical URIs)
- [Lynch]
- Data compression: techniques and applications. Thomas J. Lynch. New York : Van Nostrand Reinhold, c1985.
- [Marsh74]
- Marsh holds place of honor in history of GS1 barcode, GS1, June 2014
- [Matrix]
- Matrix URIs, Matrix spaces and Semicolons. Tim Berners-Lee, 19 December 1996
- [REST]
- Representational State Transfer (REST) from Architectural Styles and the Design of Network-based Software Architectures. Roy T Fielding's PhD. thesis from 2000
- [RFC20]
- ASCII format for Network Interchange. V. Cerf. IETF 16 October 1969.
- [RFC777]
- Internet Control Message Protocol. J. Postel. IETF, April 1981.
- [RFC1738]
- Uniform Resource Locators (URL). T Berners-Lee, L Masinter, M McCahill, IETF December 1994. See in particular section 3.3.
- [RFC1808]
- Relative Uniform Resource Locators, R. Fielding. June 1995
- [RFC2068]
- Hypertext Transfer Protocol -- HTTP/1.1. R. Fielding, J. Gettys, J. Mogul, H. Frystyk, T. Berners-Lee. IETF January 1997. See sections on language, authorisation, content negotiation and redirection.
- [RFC2396]
- Uniform Resource Identifiers (URI): Generic Syntax. T. Berners-Lee, R. Fielding L. Masinter. August 1998
- [RFC3548]
- The Base16, Base32, and Base64 Data Encodings. S. Josefsson, Ed. IETF July 2003
- RFC3875]
- The Common Gateway Interface (CGI) Version 1.1. D Robinson, K. Coar.IETF October 2004
- [RFC5234]
- Augmented BNF for Syntax Specifications: ABNF, D. Crocker, Ed, P. Overell, IETF January 2008
- [Salomon]
- Data Compression: The Complete Reference; David Salomon; Published by Springer-Verlag (1998); ISBN 10: 0387982809 ISBN 13: 9780387982809. The fourth edition from 2007 was available online (broken link removed).
- [Unicode]
- ISO/IEC 10646:2017 Information technology — Universal Coded Character Set (UCS) ISO/IEC JTC 1/SC 2. ISO/IEC Standard December 2017
Footnotes
- The code in the 2008 document is so old it uses the now obsolete <tt> element which I 'updated' to <code>
- That document includes strong evidence that Tim was using a spell checker but, as ever, his words were several steps behind his thoughts. It makes more sense of you read 'pause' as 'parse' for example.
- GS1 doesn't routinely keep all old versions of its standards online but a copy of version 1.3 (pdf) is here as a historical reference (see also the current version).
Notes from Keith Jeffery
I am very grateful to Keith Jeffery for his notes on this topic which I include below with his permission.
The background is that my Division within the computing department at RAL was essentially engaged on EC-funded and UK-funded research projects although we also did work for the scientific and management systems of the lab. In the period 1992-1997 we did a lot of work on information systems trying to combine hypermedia with database technology. Simon was in the software engineering team and Victoria in the hypermedia team. Their cooperation was very fruitful. My role was simply to suggest, criticise (positively), encourage and assist. I think my only real personal contribution was suggesting initially that we could have HTML attributes corresponding to the named items (entities, attributes...) in the schema of a RDBMS. Simon may remember it differently, of course. The 'lightweight database' approach was only one of the experiments (and leaned towards the multimedia/hypermedia approach) and, in different experiments as I recall, we did generate from query templates (structure driven by a RDBMS schema) queries extending http URLs which were picked up by a RDBMS 'front-end' and converted to a classical RDBMS query within the RDBMS environment.
My recollection (necessarily hazy after almost 40 years) is that we discussed query strings within / attached to the URL with the query being essentially SQL syntax (e.g. Name = "Jeffery" or Price > 999). In fact we implemented several systems - including the system for providing web pages on people, projects etc) using URLs with queries aimed at a RDBMS with a schema that was a primitive form of the later CERIF (broken link removed) (formalised in 1997 and which you know from VRE4EIC).
In the paper Lightweight Databases BCS 1995, Dobson & Burrill, the following quotes appear (with my comment in brackets):
For this paper we shall concentrate on an experiment which we have conducted into improving search techniques for WWW pages.
(note search techniques)
A number of authors have investigated using WWW to access a relational database management system (RDBMS) using a “gateway” to generate queries and convert the results into HTML.
(this indicates that we were early in this game but maybe not the first).
A number of authors have investigated using WWW to access a relational database management system (RDBMS) using a “gateway” to generate queries and convert the results into HTML.
(this is a criticism of the earlier pre-defined query work indicating we were going for user-defined queries)
we have a representation of the information which may be browsed using WWW clients or queried using a database-like query engine
(the dual means of access approach - you have heard me extol this in VRE4EIC and elsewhere - but note the need for queries with the query elements corresponding to (a) HTML tags; (b) RDBMS schema elements)
In particular, it is important to realise that the lightweight database's entities are connected using relationships, not hyperlinks: the hyperlink structure of a set of pages can be different from the relationship structure of the database, and typically the former will be significantly richer than the latter. (You have heard me say this also in VRE4EIC; the limitations of hyperlinks are because of their limited semantics (just look at XLINK for example); RDF does better but for real expressivity you need n-tuples (with temporal information and maybe modal logic) as in CERIF).
One way to improve searching is to move more towards embedded RDBMSs, allowing queries to be presented directly to a search engine. (this indicates we understood this idea of an embedded query string)
An alternative is to provide a query engine which understands the lightweight database notation and can query pages directly. We have implemented a simple template-driven query engine which can perform arbitrary queries on a lightweight database, returning the results as an HTML page. (between the query template and the lightweight database I think there must have been http with URLs with query strings for this to work).
Much of the infrastructure already exists, as the hypertext transfer protocol (HTTP) used in WWW is far more general than current browsers would indicate. As well as object acquisition it supports arbitrary object types admitting user-defined methods, and has sufficient power to act as the transport mechanism for a lightweight distributed object system. (this confirms we understood how to use URLs beyond a simple target address).
Keith added: In this work the real need was to reconcile a hypermedia / user authoring view with an information systems (database and update) view. I think the team was pretty successful in bringing the ideas together.