Fear of RDF
Yesterday I received tweet that said: @philarcher1 when I hear "Open Data" I always fear it's RDF.
Is that the case or are these new open data initiatives more Web friendly?
Even a cursory look at the sender's Web site shows you that he's a very knowledgeable programmer who is particularly skilled in JavaScript. I know him virtually through the W3C's Mobile Web courses (one of which I teach) and it's clear he knows his stuff.
This tweet however strongly suggests that he's so entrenched in one world view that he rejects any other out of hand. I know this not to be the case but it is the impression given in the limited circumstances of 140 quickly written characters. This is not helpful.
JavaScript allows you to create highly engaging Web content that is dynamic and interactive. If you’re good at it (and this person is) then you can get a browser to do extraordinary things these days, including, literally, making it sing (through the audio API). The data exchange method used by JavaScript, JSON, is very powerful and all the modern browsers have built-in support for it. Nothing wrong with JSON, nothing wrong with JavaScript.
What saddens me of course is the rejection of RDF. Some basics:
- JavaScript is a programming language that allows you to do clever things in a Web browser;
- JSON is a simple data exchange format that encodes name/value pairs and arrays;
- RDF is a data model that allows you describe the real world;
- the real world can be complicated and messy;
- Linked Data is an application of RDF that allows disparate data sources to enrich each other.
To 'fear RDF' is as silly as to fear wooden spoons — different tools for different jobs.
Can you not enrich (mix) data with JSON? Of course you can, but you do it by matching one table with another in a relational-database sort of way. Again, nothing wrong with relational databases it's just that RDF is better for some things, like publishing datasets in such a way that encourages re-use in ways that the publisher themselves may not have thought of. A tabular data set is essentially two dimensional, and, to emphasise, very good for a lot of things. RDF is multi-dimensional and good for a lot of other things. The two overlap, but not by 100%.
At the Uses of Open Data workshop I ran recently, I saw a couple of examples where the power of linked data is making a real difference. The Renewable Energy and Energy Efficiency Partnership, Reegle [broken link removed], collects and triplifies data from many different sources to present a lot of domain-specific information in different ways. Similarly, publicspending.gr [broken link removed] collects data from different sources, triplifies it and presents it in useful ways. In both cases, the aggregated data is made available as linked data that can be accessed using the same query language and tools that are used in the applications themselves. Try doing that in JSON. You can, yes, but it's a lot easier to use RDF for that kind of thing.
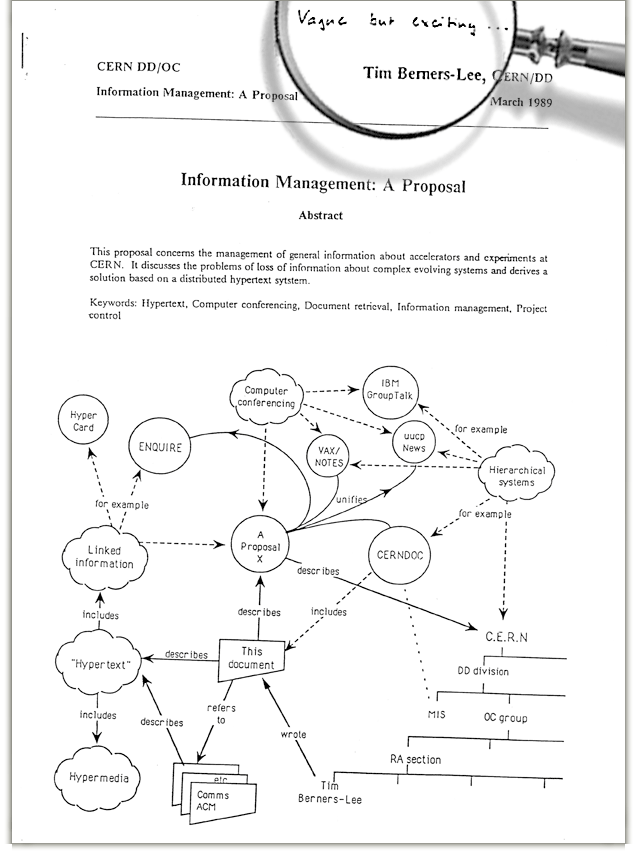
The idea that RDF is not Web friendly is, well, arrant nonsense. RDF is based on using URIs to identify things and relationships between them. If you restrict the use of RDF to using URIs that begin http: and follow a set of simple best practices, you get Linked Data which is how you do data at Web scale. That is, a massively distributed data set that anyone can contribute to, just like they can to the Web of documents. The idea of using URIs to link data is right there in TimBL's original paper from 1989. The Web of Data is woven into the very fabric of the Web.
But there's more.
One of the reasons some public sector officials are reluctant to publish their data is that they fear that it will be misused. Notably the fear is that some of the important detail in the data will be missed. Tabular data typically includes annotations "beware this is an estimate" or "this value is missing because of XYZ". That kind of data is an important part of the story and it's vital that developers take note — those annotations and the general metadata that goes with any data set are what tell you the context in which the data was gathered, what it does and does not represent. To encode that you need rather more than name/value pairs and the odd array. I said more about this in a recent keynote.
Religious wars that reduce to "my technology's better than your technology" are always counter productive. That said, I do think that the linked data community does need to do more to make developers' lives easier. JSON-LD is a really good start, so is R2RML and I'm looking forward to seeing what comes out of the heavily JSON-centric Data Protocols [broken link removed] work announced this week by the Open Knowledge Foundation.
But please don't fear RDF and don't tell me that it's not Web friendly.