Danbri has moved on – should we follow?
The other day I spent 20 minutes or so absorbed in this talk by Dan Brickley [embedded video/broken link removed] and since then I've been giving it a lot of thought. If you have had any connection with Linked Data or the wider Semantic Web you probably know Dan personally and will certainly be well aware of his work. Dan is one of the original architects of he Semantic Web, not only co-editing the RDF-S spec with R V Guha but also creating some of the oldest and most widely used RDF vocabularies in the linked data world: the Basic Geo (WGS84 lat/long) Vocabulary and, most famously, FOAF. Dan is a big part of the RDF/Linked Data story.
I first met him roughly 10 years ago when he was at ILRT in Bristol, working in an office alongside Dave Beckett, Max Froumentin and Libby Miller. I admit I was somewhat star struck to walk into that room.
Enough history, what's the story here? It's this:
(at 14:10) In the RDF community, in the Semantic Web community, we're kind of polite, possibly too polite, and we always try to re-use each other's stuff. So each schema maybe has 20 or 30 terms, and... schema.org has been criticised as maybe a bit rude, because it does a lot more it's got 300 classes, 300 properties but that makes things radically simpler for people deploying it. And that's frankly what we care about right now, getting the stuff out there. But we also care about having attachment points to other things…
I now spend a lot of time working on vocabularies1, some in areas that are already well served by existing vocabularies. For example, I've been working on one to describe a person. There are a lot of ways of describing a person already, Dan and Libby's FOAF vocabulary being the preeminent one, but they don't quite cover the use cases that public administrations have and we needed a bit more. Having created a concept scheme for the vocabularies I was working on (with a working group set up by the EU's ISA Programme) I then had to write the RDF schema. Here are some of the conceptual properties for which I needed to find terms, along with the choices of existing vocabulary terms I made:
| Conceptual term | Term chosen |
|---|---|
| full name | foaf:name |
| given name | foaf:givenName |
| family name | foaf:familyname |
| gender | schema:gender |
| date of birth | schema:birthdate |
| date of death | schema:deathDate |
Alongside these there were 8 others for which I have had to mint new terms.
That, surely, is best practice for the RDF community? Whether you agree with the specific choices I made, you'd probably do something similar? i.e. look at existing vocabularies, particularly ones that are already widely used and stable, and re-use as much as you can. Dublin Core, FOAF – you know the ones to use.
Except schema.org doesn't.
schema.org has its own term for name, family name and given name which I chose not to use at least partly out of long term loyalty to Dan. But should that affect me? Or you? Is it time to put emotional attachments aside and move on from some of the old vocabularies and at least consider putting more effort into creating a single big vocabulary that covers most things with specialised vocabularies to handle the long tail?
You've probably seen this diagram before …
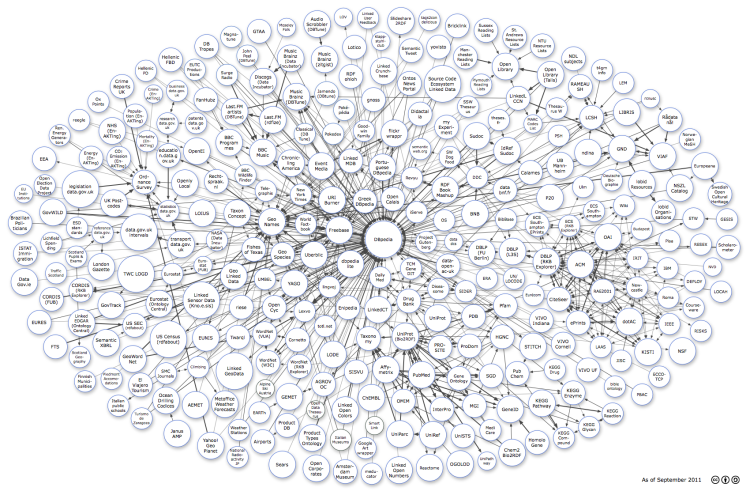
Actually, you've probably seen it in every talk on Linked Data you've ever seen and used it in any talk you've ever given. The LOD cloud diagram emphasises links between data sets and shows how one set relates to another. Anja Jentzsch and Richard Cyganiak have been praised widely for this work – it's the diagram that set the Linked Data movement in motion.
Seen this one?

It's Dan's diagram of the schema.org vocabulary. And it's very different from the LOD cloud.
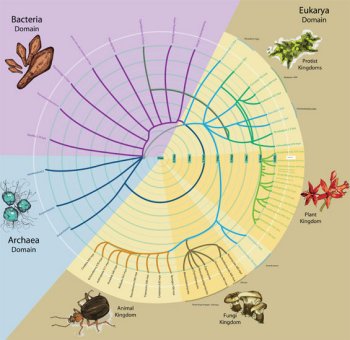
It says "here are the things people are interested in searching for and this is how we're arranging them." As Dan's talk shows, search terms have barely changed in style for 100 years and more. It serves a different purpose and so, of course, it looks very different. It's the same sort of diagram that is often used, for example, to show evolutionary relationships in the 'Spiral of Life.' I have a feeling it will become as ubiquitous as the LOD cloud.
Maybe it's time to let go of our emotional attachment to treasured old friends like FOAF and embrace schema.org as the vocabulary to use wherever possible? It won't cover everything, but it might cover the 50% of classes and properties that dominate any domian of interest. As Dan is quick to point out, it's still only a fraction of human knowledge. See, for example, this visualisation [broken link removed] of the differences between the category structure of Wikipedia and the Universal Decimal Classification (UDC) system. The diagram below shows a possible future — if we want it.

And if you were someone like R.V. Guha, now at Google, and you wanted to create one big schema that covered the main things people were typically interested in, how would you do it? I suggest you'd do it by:
- securing large scale industry backing — say, from the other major search engines;
- hire one of the most respected people in the Semantic Web community to work on it with you, preferably one who you'd worked with closely before, and get him/her to build a community around the project, perhaps starting with a W3C mailing list.
As Dan Brickley says: …that makes things radically simpler for people deploying it. And that's frankly what we care about right now …
Comments
Vassilios Peristeras wrote:
Very interesting post. Some thoughts …
Big ontologies (top-down structure), decentralized linked (big) data (bottom-up structure), and now again to some structure… schema.org: it looks like a pendulum to me that goes from total control to total anarchy and back.
IMHO, the core of the semantic web remains on "semantic agreements" at a large scale (on the web). And this is what you discuss here.
Semantic agreements are social products of a social process. I don't think we have yet understood the dynamics of this process, neither the quality characteristics of the products.
People at some point thought that we can develop huge ontologies to describe the world (e.g. cyc). Then, the semantic web could emerge simply by using these huge ontologies to annotate web resources. Today, it is rather a common ground that this is an utopia: people cannot agree on huge ontologies, at least this seems very difficult to happen during this century, who knows what happens in 2100 . A similar type of semi-holistic semantic agreements may be developed and cater specific domains (e.g. UDC) but the challenge is to have such specifications accepted and used cross-domain by different communities on the web.
As a response to this semantic web dead-end, recently the RDF and linked data community, showing a clear dislike in "heavy ontologies", top-down and centralized approaches claimed exactly the opposite: they urged us a. to use RDF, b. publish the result on the web, and do not care about the schema and metadata. We can do the mappings later.
I think these are rather the two extremes of the spectrum that goes from "the one and unique world ontology" to the Babel tower of "rdf-ise everything without caring about the schema". The limitations of both are rather clear despite the fact that there are supporters of both the extremes.
So the question remains: how could we reach semantic agreements?
The closest equivalent we have to learn from is perhaps the area of technical standards: technical standards are agreements at the technical level. There is an industry that has been set up for this: standardization activities, bodies and experts help us agreeing on technical standards that improve interoperability at the technical layer (see the EIF layers as a reference). Now, we raise the discussion and talk about the need to develop "semantic standards", that is semantic agreements at the semantic interoperability level. Is the technical standards industry ready to cater the needs and requirements for semantic agreements? I seriously doubt that this is so. Methods and tools can be reused but also be adapted to the semantic layer. Both the process and the quality of semantic standards (whatever this may mean) should be discussed and defined.
How "semantic standards" look like? During my work in the ISA unit, I spent a lot of time reflecting on this: I ended up defining semantic standards as reusable reference data (e.g. codelists, taxonomies) or reusable metadata (e.g. XML schemas, RDFS, ontologies). The "reusable" element of the definition clearly shows a subjective aspect on what qualifies to be called "semantic standard" (or "semantic assets" according to the ISA terms).
And then the next question comes: what could/should we try to standardize on a web scale (not in specific domains as this is a different discussion)? Which means from where we should start our large-scale agreements on semantics? The top-down approach has been tried (ontologies) and failed in the large (web) scale. The attractive liberty of publishing rdf and do not care for metadata has also reached its limits, unless we really believes that with "SameAs" and "SeeAlso" we can solve all semantic interoperability problems that have been identified during the last decades. The approach could be simple: lets try to standardize what almost all people already agree on, or lets standardize those that less people would disagree with. That was exactly the idea of the ISA core vocabularies. The approach is minimalistic: minimum set of agreements, minimum common denominator amongst different groups, domains, perspectives. Because we know the human nature: people like to disagree with what others say (thanks god!). So, I don't expect the universe in 2012 to agree on the schema.org 300 terms (not to mention the who, how and why questions on schema.org, what I previously called "the process" for social agreements), but I do hope that we could agree on 10 terms to describe a person. I also noticed in the video that schema.org expands itself to cover Job Posting, News, eCommerce and many more. Where is the limit? Do they create little by little cyc 2.0? And based on what? On the "augmented search results" use case? Is this enough?
It is as simple as this: let's start with 5 agreements on some basic entity first. Then we could make them 10, 20, or 300. By 2100 we could agree on cyc, or on one ontology for the universe, who knows. But I do believe that we should start with 5 and with a different social process. After all, search engines should serve the web and not the other way around…
Kerstin Forsberg followed up this article with one of her own: Describe things vs Improve markup of pages that describe things.